Intro to Retrieval Augmented Generation
// DEFINITION:
01. What is RAG?
Retrieval-Augmented Generation (RAG) is an architecture that connects a large language model (LLM) to an external knowledge source, allowing it to retrieve relevant, up-to-date information at the moment it generates a response — rather than relying solely on the static knowledge it absorbed during training. In plain terms: RAG gives an AI model a library card. Instead of asking it to answer everything from memory, you let it look things up first.
The term originates from a 2020 research paper by Meta AI (then Facebook AI Research), which introduced RAG as a way to combine a pre-trained generative model with a retrieval component that pulls from a non-parametric memory — typically a dense vector index of documents. The core idea has barely changed since, even as the surrounding ecosystem has grown enormously: a generative model is paired with an external knowledge source, and the two work together at the moment of inference.
1.1. How RAG Differs from Standard LLM Inference:
- A standard LLM operates entirely on parametric knowledge — everything it "knows" is encoded in its model weights, frozen at the point training ended. Ask it about something outside that training data — your company's internal pricing policy, a product launched last month, or a niche regulation — and it has two options: admit it doesn't know, or guess. The second option is where hallucinations come from.
- RAG changes this by introducing a retrieval step before generation. The model's prompt is no longer just your question — it's your question plus a set of relevant passages pulled from an external knowledge base in real time. The LLM then generates its answer using both its general language ability and the specific facts handed to it. Retrieval-Augmented Generation (RAG) is a framework that augments the general knowledge of a generative LLM by providing it with additional data relevant to the task at hand, retrieved from an external data source — and crucially, this happens at inference time, without retraining the model itself.
The one-sentence version: a RAG pipeline is essentially retrieval + prompt augmentation + generation — three steps that turn a closed-book exam into an open-book one, every single time the model is asked a question.
// THE PROBLEM IT SOLVES:
02. Why is RAG Important?
Every large language model has three structural limitations baked into its design — and RAG was designed specifically to address all three.
2.1. The Knowledge Cutoff Problem:
- An LLM's training data has a hard stop date. Anything that happened after that date — a new product release, a policy change, a market shift — simply doesn't exist in the model's "mind." Retraining a frontier model from scratch to incorporate new information costs millions of dollars and takes months. RAG sidesteps this entirely: instead of retraining the model, you update the external knowledge base, and the model's answers reflect the new information immediately.
2.2. The Hallucination Problem:
- When an LLM doesn't know something, it doesn't always say so — it often generates a fluent, confident-sounding answer that is simply wrong. This "tendency to generate incorrect or fabricated information convincingly" is what the industry calls a hallucination, and in client-facing applications, it can cause real reputational damage. RAG attacks this at the source: studies show RAG can reduce hallucination rates by 40 to 71% across benchmarks like Vectara's HHEM Leaderboard for top models in 2025, because the model is now grounding its response in retrieved text rather than reconstructing facts from compressed training data.
2.3. The Static Training Data Problem:
- LLMs are trained on broad, general-purpose datasets — books, websites, code, articles. They are not trained on your company's internal wikis, your product's support tickets, your legal team's contract templates, or your latest financial reports. This isn't a bug; it's simply outside the scope of what a general-purpose model can know. RAG is the bridge that lets a general-purpose model become a domain expert — at query time, without ever touching the model's weights.
By 2026, this pattern will have become foundational rather than optional. As one industry analysis put it, sources consistently highlight that RAG aligns with enterprise priorities around accuracy, explainability, compliance, and cost efficiency — RAG is not just an AI technique, it's a systems architecture choice that reshapes how enterprises operationalize knowledge.
// THE PAYOFF:
03. What are the Benefits of RAG?
RAG isn't just a technical workaround for hallucinations — it changes the economics, safety profile, and reach of an AI system. Here are the seven benefits that matter most.
BENEFIT 01:
Cost-Efficient AI Implementation & Scaling:
- Fine-tuning a large model on new information requires significant computational resources, specialized ML engineering talent, and ongoing retraining cycles every time the underlying information changes. RAG dramatically lowers this barrier. Rather than retraining a multi-billion-parameter model, teams update a vector database — an operation that's orders of magnitude cheaper and can happen continuously. RAG enables dynamic updates without retraining the entire model, which translates directly into lower compute costs, faster iteration, and the ability to scale an AI application across many domains without spinning up a custom model for each one.
BENEFIT 02:
Access to Current and Domain-Specific Data:
- Fine-tuning a large model on new information requires significant computational resources, specialized ML engineering talent, and ongoing retraining cycles every time the underlying information changes. RAG dramatically lowers this barrier. Rather than retraining a multi-billion-parameter model, teams update a vector database — an operation that's orders of magnitude cheaper and can happen continuously. RAG enables dynamic updates without retraining the entire model, which translates directly into lower compute costs, faster iteration, and the ability to scale an AI application across many domains without spinning up a custom model for each one.
BENEFIT 03:
Lower Risk of AI Hallucinations:
- Fine-tuning a large model on new information requires significant computational resources, specialized ML engineering talent, and ongoing retraining cycles every time the underlying information changes. RAG dramatically lowers this barrier. Rather than retraining a multi-billion-parameter model, teams update a vector database — an operation that's orders of magnitude cheaper and can happen continuously. RAG enables dynamic updates without retraining the entire model, which translates directly into lower compute costs, faster iteration, and the ability to scale an AI application across many domains without spinning up a custom model for each one.
BENEFIT 04:
Increased User Trust:
- Fine-tuning a large model on new information requires significant computational resources, specialized ML engineering talent, and ongoing retraining cycles every time the underlying information changes. RAG dramatically lowers this barrier. Rather than retraining a multi-billion-parameter model, teams update a vector database — an operation that's orders of magnitude cheaper and can happen continuously. RAG enables dynamic updates without retraining the entire model, which translates directly into lower compute costs, faster iteration, and the ability to scale an AI application across many domains without spinning up a custom model for each one.
BENEFIT 05:
Expanded Use Cases:
- Fine-tuning a large model on new information requires significant computational resources, specialized ML engineering talent, and ongoing retraining cycles every time the underlying information changes. RAG dramatically lowers this barrier. Rather than retraining a multi-billion-parameter model, teams update a vector database — an operation that's orders of magnitude cheaper and can happen continuously. RAG enables dynamic updates without retraining the entire model, which translates directly into lower compute costs, faster iteration, and the ability to scale an AI application across many domains without spinning up a custom model for each one.
BENEFIT 06:
Enhanced Developer Control & Model Maintenance:
- Fine-tuning a large model on new information requires significant computational resources, specialized ML engineering talent, and ongoing retraining cycles every time the underlying information changes. RAG dramatically lowers this barrier. Rather than retraining a multi-billion-parameter model, teams update a vector database — an operation that's orders of magnitude cheaper and can happen continuously. RAG enables dynamic updates without retraining the entire model, which translates directly into lower compute costs, faster iteration, and the ability to scale an AI application across many domains without spinning up a custom model for each one.
BENEFIT 07:
Greater Data Security:
- Fine-tuning a large model on new information requires significant computational resources, specialized ML engineering talent, and ongoing retraining cycles every time the underlying information changes. RAG dramatically lowers this barrier. Rather than retraining a multi-billion-parameter model, teams update a vector database — an operation that's orders of magnitude cheaper and can happen continuously. RAG enables dynamic updates without retraining the entire model, which translates directly into lower compute costs, faster iteration, and the ability to scale an AI application across many domains without spinning up a custom model for each one.
// IN PRACTICE:
04. RAG Use Cases:
RAG's real value becomes obvious when you see it applied to specific, everyday business problems. Here are six categories where it's reshaping how organizations build AI products.
4.1. Specialized Chatbots & Virtual Assistants:
General-purpose chatbots give generic answers. A RAG-powered assistant grounded in your product manuals, FAQs, and support tickets can answer detailed, product-specific questions — troubleshooting steps, warranty terms, configuration options — accurately and consistently.
Real-World Example:
An electronics company builds a customer support chatbot that answers questions about specific device models by retrieving from its actual user manuals and troubleshooting databases — rather than giving the vague, generic responses a base LLM would produce for a product it was never specifically trained on.
4.2. Research:
Researchers and analysts spend enormous amounts of time reading through papers, reports, and literature to find relevant findings. RAG-powered research tools retrieve and synthesize information across large document collections, surfacing the specific passages relevant to a research question along with citations back to the source.
Real-World Example:
A medical research assistant retrieves relevant findings from clinical literature and treatment guidelines to support a clinician's question about a specific drug interaction — citing the exact studies it drew from, which is critical for verification in high-stakes fields like healthcare.
4.3. Content Generation:
RAG can use content from external sources to produce accurate summaries and drafts grounded in real, current information — rather than the generic or outdated output a base model might produce. This is especially valuable for content that needs to reflect the latest data, statistics, or company messaging.
Real-World Example:
Managers and executives who don't have time to read lengthy reports use a RAG-powered summarization tool to quickly extract the most critical findings from quarterly reports, market research, or competitor analyses — turning a 50-page document into a digestible brief grounded in the actual source material.
4.4. Market Analysis & Product Development:
Organizations make decisions by tracking competitor behavior, market trends, and customer sentiment. RAG models can connect to the internet via APIs and gain access to real-time social media feeds and consumer reviews for a better understanding of market sentiment — feeding directly into product roadmaps and go-to-market strategy.
Real-World Example:
A product team builds a RAG pipeline that retrieves and synthesizes recent customer reviews, support tickets, and social media mentions about a product line, generating a weekly digest of emerging pain points and feature requests that feeds directly into sprint planning.
4.5. Knowledge Engines:
Large organizations sit on enormous internal knowledge bases — wikis, policy documents, engineering docs, onboarding materials — that are notoriously hard to search effectively. RAG turns this sprawling, siloed information into a conversational interface, letting employees ask natural-language questions and get answers grounded in the actual internal documentation.
Real-World Example:
An employee policy copilot answers HR, travel, and benefits questions with citations and effective dates, reducing help-desk load and speeding up onboarding — employees get instant, accurate answers instead of digging through a 200-page employee handbook.
4.6. Recommendation Services:
Traditional recommendation systems require sophisticated ensemble models and massive user preference datasets. RAG simplifies this by directly integrating external, contextually relevant user data — purchase history, reviews, viewing patterns — with the model's general language understanding, producing recommendations that are more nuanced and explainable than those of a traditional collaborative filtering system.
Real-World Example:
A streaming platform's recommendation assistant retrieves a user's viewing history and recent ratings, then generates personalized movie suggestions with natural-language explanations of why each title was chosen — something a traditional recommendation engine can't articulate.
// The Pipeline:
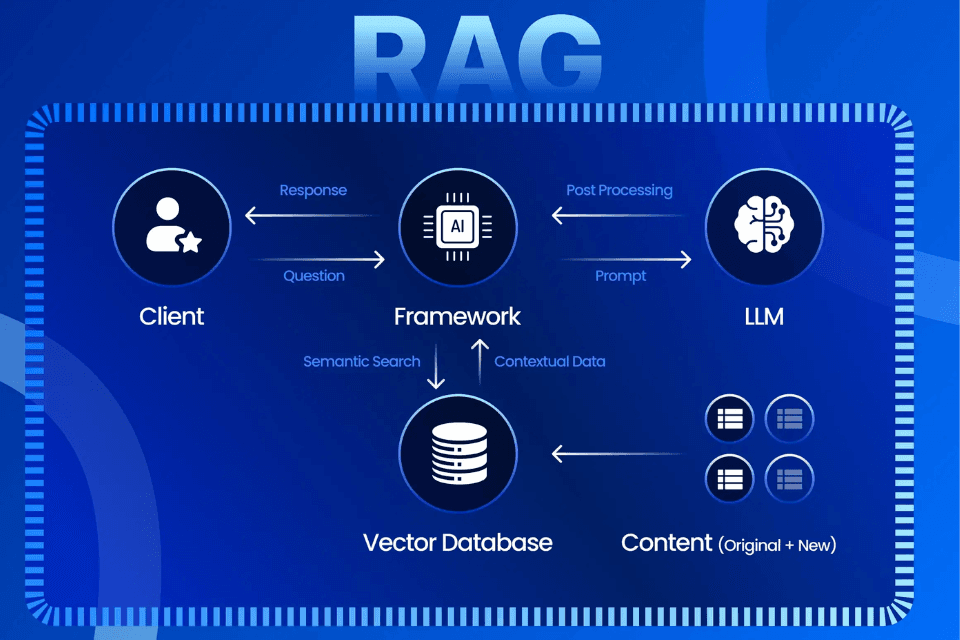
05. How Does RAG Work?
A RAG system operates in two distinct stages: ingestion, which happens before any user ever asks a question, and inference, which happens every time a question is asked. Understanding both stages — and the steps within each — is the key to understanding RAG.

Stage 1 — Ingestion (Happens Once, Then Continuously):
1. Data Collection:
- Gather all the source material the system should be able to draw from — user manuals, internal wikis, product databases, FAQs, contracts, or scraped webpages. This becomes the system's external, non-parametric knowledge.
2. Chunking:
- Long documents are broken into smaller, focused pieces. A 100-page manual might be split into sections, each addressing a specific topic — so that when a piece of information is retrieved, it's directly applicable to the user's query rather than burying the relevant fact inside an entire document.
3. Embedding & Vectorization:
- Each chunk is converted into an embedding — a numeric vector that captures its semantic meaning. This allows the system to match queries to content based on meaning, not just keyword overlap.
4. Indexing & Storage:
- Embeddings are stored in a vector database, optimized for fast similarity search across potentially millions of chunks. This indexed store becomes the system's reusable, searchable knowledge base.

Stage 2 — Inference (Happens Every Time a User Asks a Question)
5. Query Embedding:
- The user's question is converted into an embedding using the same model used to embed the knowledge base — ensuring the query and the documents live in the same semantic space and can be directly compared.
6. Retrieval:
- The system performs a similarity search, calculating the distance between the query embedding and the stored document embeddings using measures like cosine similarity. The chunks with the shortest distance — the most semantically relevant — are retrieved. In production, retrieval quality is heavily influenced by chunking strategy and how content is indexed for search and filtering.
7. Augmentation:
- The retrieved chunks are inserted into a prompt template alongside the original user query — the bridge that hands the model contextually relevant information at exactly the moment it needs it.
8. Generation:
- The augmented prompt is passed to the LLM, which combines its internal language understanding with the retrieved external facts to produce a fluent, accurate, and contextually appropriate final response — ideally with citations back to the source material.

// The Architecture:
06. Components of a RAG System:
While the workflow above describes the process, it also helps to think in terms of the four structural components that make up any production RAG system. Each can be built, scaled, and optimized somewhat independently.
6.1. The Knowledge Base:
- The external, non-parametric data source — internal databases, documents, codebases, legal texts, scientific literature, or scraped web content. In agentic systems, this knowledge base is often treated as a form of long-term memory the agent can draw from as needed. It's typically stored as a vector index, but can also include structured databases, knowledge graphs, or live API connections for real-time data.
6.2. The Retriever:
- The component responsible for finding the most relevant pieces of information given a query. At its simplest, this is a similarity search over embeddings — but production retrievers often combine dense vector search with keyword-based sparse retrieval (hybrid search), apply metadata filters, and use a reranking model to sort results by true relevance before passing them on.
6.3. The Integration Layer:
- The "glue" — typically a prompt template — that combines the retrieved context with the user's original query into a single, well-structured prompt.
- This layer determines how context is formatted, how much context fits within the model's context window, and how instructions are framed so the model uses the retrieved information correctly rather than ignoring it.
6.4. The Generator:
- The LLM itself — the component that takes the augmented prompt and produces the final, human-readable response. The generator combines its own internal language understanding and reasoning ability with the newly retrieved data, producing an answer that is both fluent and grounded in the provided facts.
Building these components from scratch isn't necessary. Frameworks like LangChain (with LangGraph for agentic pipelines and LangSmith for evaluation), LlamaIndex (and its LlamaHub repository of data loaders and tools), and DSPy (a modular framework for optimizing LLM and retrieval pipelines together) provide pre-built building blocks for all four components, along with integrations to vector databases like Weaviate, Pinecone, and others.
// The Toolkit:
07. All RAG Techniques:
The "vanilla" RAG pipeline described above is just the starting point. A 2024 comprehensive RAG benchmark found that state-of-the-art RAG systems answer only 63% of factual questions correctly, while straightforward retrieval without advanced techniques scores just 44% — which is exactly why the field has produced an entire toolkit of techniques to close that gap. Here's the full spectrum, organized roughly from foundational to frontier.
Naive RAG
The original pattern: embed documents, store them in a vector database, retrieve via similarity search, stuff into a prompt template, and generate. Simple, fast to build, and the baseline that every other technique improves upon.
Advanced RAG
An umbrella term for pre- and post-retrieval optimizations applied to naive RAG: metadata filtering and smarter chunking to narrow the search space before retrieval; hybrid search that combines dense vector similarity with sparse keyword search; and reranking retrieved results with a dedicated ranker model before they reach the generator. Each of these can be deployed independently and stacked together.
Modular RAG
Rather than a fixed linear pipeline, Modular RAG treats each stage — retrieval, reranking, query rewriting, generation — as a swappable, LEGO-like module. This makes it possible to mix and match different retrieval strategies, route different query types to different modules, and continuously improve individual components without rebuilding the whole pipeline.
HyDE (Hypothetical Document Embeddings)
Instead of embedding the user's query directly — which is often short and vague compared to the documents it needs to match — HyDE first asks the LLM to generate a hypothetical answer to the query, then embeds that hypothetical document and uses it for retrieval. This works because a hypothetical answer is structurally more similar to a real document than a short question is, dramatically improving retrieval matching for sparse or ambiguous queries. HyDE matches fine-tuned dense retrievers on standard benchmarks without any labeled training data, and is now standard in LangChain, LlamaIndex, and Haystack.
RAPTOR
Recursive Abstractive Processing for Tree-Organized Retrieval. Rather than treating all chunks as flat and equal, RAPTOR builds a recursive tree by clustering related chunks and generating summaries at each level — creating a hierarchy from granular detail up to high-level themes. This lets the retriever pull either fine-grained facts or broad summaries depending on the question, which is especially valuable for "global" questions that span an entire document or corpus.
Self-RAG
A reflective approach where the model is trained to decide when retrieval is even necessary, and to critique its own draft responses against the retrieved context — checking whether claims are actually supported before finalizing an answer. Self-RAG boosts factuality and citation accuracy across QA and long-form tasks by adding this self-reflection loop directly into the generation process.
Corrective RAG (CRAG)
CRAG adds a quality-scoring step after retrieval: a lightweight evaluator assesses whether the retrieved documents are actually relevant and sufficient. If the retrieved context is judged poor, the system can fall back to alternative strategies — such as a live web search — rather than passing weak context straight to the generator. This significantly reduces the "garbage in, garbage out" failure mode of naive retrieval.
Graph RAG
While traditional RAG excels at pinpoint factual questions, it struggles with "global" questions that require synthesizing information across an entire corpus — like "what themes emerge across this body of documents?" Graph RAG solves this by using an LLM to build a knowledge graph that extracts entities and the relationships between them, then organizes the corpus into community summaries. Microsoft Research's GraphRAG demonstrated query-focused summarization by moving from local passages to global structure. A newer variant, LazyGraphRAG, defers expensive summarization until query time, cutting GraphRAG's indexing cost to roughly 0.1% of the original approach while matching or beating vector RAG and RAPTOR on benchmark accuracy.
Agentic RAG
The most significant shift in the 2025–2026 era. Instead of a fixed, single-hop retrieval pipeline, autonomous agents plan multiple retrieval steps, choose which tools to use, reflect on intermediate answers, and adapt their strategy for complex, multi-step tasks — such as comparing information across multiple documents or running a compliance check across many systems. Retrieval becomes just one "tool call" among many in a flexible, dynamic workflow, where "LLM-as-judge" agents check whether an answer is complete, relevant, and factually grounded before it's returned to the user. Agentic iterative RAG has been shown to outperform earlier iterative retrieval-generation approaches by a meaningful margin on multi-hop reasoning benchmarks.
Adaptive-RAG & RAG-Fusion
Adaptive-RAG dynamically routes queries based on their complexity — simple factual questions might skip retrieval entirely or use a single-hop search, while complex multi-part questions trigger more elaborate multi-step retrieval. RAG-Fusion generates multiple reformulations of the original query, retrieves results for each, and merges the ranked results — capturing relevant documents that a single query phrasing might have missed.
Contextual Retrieval
Introduced by Anthropic, this technique addresses a subtle but common failure: individual chunks often lose important context when split from their surrounding document (a chunk might say "the company's revenue grew 3%" without specifying which company or which quarter). Contextual Retrieval prepends chunk-specific explanatory context — generated by an LLM — to each chunk before embedding, which has been shown to reduce retrieval failures by a significant margin.

By 2026, the field will have largely moved past "RAG or not?" as the central question. The more useful question is what mixture of cached context, sparse and dense retrieval, graph traversal, and agentic search a particular class of query actually needs — and increasingly, systems are built to make that routing decision dynamically, per query.
// Measuring Quality:
08. How to Evaluate RAG:
A RAG pipeline has two halves — retrieval and generation — and a system can fail at either one independently. The single most important principle in RAG evaluation is therefore: measure both retrieval and generation separately. Don't just evaluate the final answer; understand where problems originate in the pipeline.
8.1 The RAGAS Framework:
RAGAS (Retrieval-Augmented Generation Assessment) has become the de facto standard framework for RAG evaluation, precisely because traditional text-similarity metrics like BLEU and ROUGE don't capture what actually matters for a RAG system: factual correctness, relevance, and groundedness in retrieved evidence. RAGAS is designed to evaluate RAG systems by measuring relevance, faithfulness, and answer completeness — and critically, it's built to require no human annotation, making continuous evaluation practical at scale.
| Evaluation Metrics | What This Metric Measures | What a Low Score Indicates |
|---|---|---|
| Faithfulness | The factual accuracy of the generated response based on the retrieved documents — computed as the proportion of claims in the answer that can be verified against retrieved chunks. | The model is hallucinating or adding unsupported claims, even when good context was retrieved. |
| Answer Relevancy | How relevant the generated response is to the original query — measured via semantic similarity between the answer and the question. | The model is answering a different (or overly broad) question than what was asked. |
| Context Precision | The proportion of retrieved chunks that actually contain query-relevant information. | The retriever is pulling in irrelevant or noisy chunks that dilute the useful context. |
| Context Recall | The percentage of information required to answer the query that actually appears somewhere in the retrieved context. | The retriever is missing important information — the knowledge base or indexing strategy needs improvement. |
8.2 Hallucination Detection:
Faithfulness is the primary defense against hallucination — it's a way to determine if your LLM is hallucinating by checking whether the generated answer is actually grounded in, and aligned with, the retrieved context. Beyond RAGAS, NLI (Natural Language Inference) models are often used to verify claim entailment: each sentence in the generated answer is checked against the retrieved context to confirm it's logically supported, not contradicted or unsupported. This is especially critical in high-stakes domains like healthcare and law, where an ungrounded claim isn't just an inconvenience — it's a liability.
8.3 The Broader Evaluation Toolkit:
RAGAS isn't the only tool in this space, and most production teams combine several: TruLens provides tracing and traceability for evaluation runs, DeepEval measures a broad set of metrics in a unified framework, DeepChecks provides robust automated testing and validation for RAG pipelines, and Arize Phoenix supports production observability — letting teams monitor retrieval and generation quality continuously as real user data flows through the system, not just during pre-launch testing.
Evaluation isn't a one-time gate. RAG quality can degrade over time as underlying data changes, document collections grow, or user query patterns shift. The most resilient teams integrate RAGAS-style metrics into their CI/CD pipeline and run continuous evaluation — not just a pre-launch benchmark.
And remember: no single metric tells the whole story. A system can have perfect context recall and terrible faithfulness, or vice versa — which is exactly why retrieval and generation need to be measured independently.
// The Decision:
09. RAG vs. Fine-Tuning:
RAG and fine-tuning are often framed as competitors, but they solve different problems — and the strongest production systems in 2026 frequently use both. The key distinction: RAG changes what the model knows by changing what it can read; fine-tuning changes what the model knows by changing its weights.
| Dimension | Retrieval Augmented Generation | LLM Fine-Tuning |
|---|---|---|
| Best for | Injecting current, factual, or proprietary knowledge | Changing behavior, tone, format, or specialized skills |
| Update speed | Near-instant — update the knowledge base, done | Slow — requires a retraining run for every meaningful update |
| Cost | Lower — primarily infrastructure for vector storage and retrieval | Higher — compute-intensive training runs, ML engineering time |
| Transparency | High — responses can cite exact source documents | Low — knowledge is embedded in weights, not traceable to a source |
| Data freshness | Always current as of the last knowledge base update | Frozen at the time of the training run |
| "Forgetting" old info | Trivial — delete or update the source document | Difficult — unlearning is an active research problem |
| Domain-specific style/format | Limited — relies on prompting to shape tone | Strong — model can deeply internalize a specific voice or output format |
| Data privacy | Strong — proprietary data never enters model weights | Weaker — proprietary data is absorbed into the model itself |
9.1. When to Use RAG:
- Choose RAG when your core challenge is knowledge — you need the model to answer questions about specific, current, or proprietary information that wasn't part of its training data. This covers the vast majority of enterprise use cases: customer support grounded in product docs, research assistants grounded in literature, internal knowledge engines grounded in company wikis. RAG is also the right call whenever your underlying data changes frequently, since the alternative — continuous retraining — simply doesn't scale.
9.2. When to Use Fine-Tuning:
- Choose fine-tuning when your core challenge is behavior — you need the model to consistently respond in a specific format, tone, or style, or to perform a specialized skill (like generating code in a proprietary internal framework, or following a very particular structured-output format) that prompting alone can't reliably achieve. Fine-tuning is also valuable when latency matters enormously, and you can't afford the extra retrieval step, or when the "knowledge" you need is more like a learned skill than a lookup-able fact.
9.3. When to Combine Both:
- The most sophisticated production systems often do both: a model is fine-tuned to better understand domain-specific terminology, follow a particular output format, or use retrieved context more effectively (sometimes called "RAG-aware fine-tuning") — while RAG continues to supply the current, factual, citable information the fine-tuned model reasons over. This combination gets the best of both worlds: a model that behaves exactly as needed, reasoning over information that's always current.
As one industry guide puts it plainly: not all tasks need RAG — in some cases, fine-tuning or even simple prompt engineering may be the better, simpler answer. The decision should follow from what's actually failing: if the model gives outdated or wrong facts, that's a retrieval problem. If the model gives correct facts in the wrong format or tone, that's often a fine-tuning (or even just prompting) problem.
// Closing:
10. Final Thoughts:
- RAG has evolved dramatically between 2024 and 2026. What once began as a relatively simple retriever-generator pipeline has matured into a sophisticated enterprise intelligence architecture — with multimodal capabilities, hybrid retrieval engines, knowledge graphs, and autonomous agents that plan, reflect, and self-correct.
- The core insight, though, hasn't changed since the original 2020 research: a model that can look things up will always be more accurate, more current, and more trustworthy than a model that can only remember. Every technique covered in this guide — from naive vector search to LazyGraphRAG to fully agentic retrieval — is, at its heart, a more sophisticated answer to the same question: how do we get the right information in front of the model at the right moment?
- For teams looking to implement RAG in production: start simple. A naive RAG pipeline with good chunking and a solid embedding model will outperform a base LLM on domain-specific tasks immediately. Then, measure before you optimize — use RAGAS-style metrics to find out whether your problems are in retrieval (precision, recall) or generation (faithfulness, relevancy) before reaching for advanced techniques. Add hybrid search and reranking when precision is the bottleneck. Add Graph RAG when users start asking "global" questions your corpus can't answer with isolated chunks. And consider agentic RAG only once you've confirmed that single-hop retrieval is genuinely the ceiling — agentic pipelines add real latency and cost, and are worth it only when the task genuinely requires multi-step reasoning.
- Heading into the rest of 2026, the trajectory is clear: retrieval is becoming less of a bolt-on feature and more of a first-class reasoning capability — woven into how models plan, verify, and act, not just how they answer questions.

